
Rethinking Reflection in Pre‑Training
In this post, we share findings from recent research at Essential AI that challenge a common belief: that reflection—the ability of language models to recognize and correct their own mistakes—only emerges during fine‑tuning or reinforcement learning.
We set out to investigate whether this reflective ability might actually begin to take shape much earlier—during pre‑training itself. To our surprise, the answer appears to be yes.
What We Mean by “Reflection”
In everyday use, reflection means thinking about how we think—noticing a mistake in some reasoning and correcting course, if necessary. For language models, we define reflection similarly: can a model detect flaws in reasoning and revise its response?
This is more than a philosophical question. If we want language models that are accurate, adaptive, and capable of backtracking from their mistakes, reflection is a crucial building block. The earlier we can cultivate it, the more efficiently we can train models and the more useful they can become.
Our Approach: Measuring Reflection During Pre‑Training
To test for reflection, we created a set of adversarial datasets across math, code, and logical reasoning. Each dataset contains misleading or incorrect “chains‑of‑thought”— reasoning steps that were plausible but led to the wrong answer.
We tested whether models could navigate past the misleading reasoning and arrive at the correct answer. In doing so, we studied two distinct forms of reflection:
- Situational reflection: overcoming incorrect prior reasoning from another source (e.g., a different model).
- Self‑reflection: correcting the model’s own previous reasoning.
To encourage this behavior, we used the single word “Wait,” as a simple trigger— analogous to a person realizing something’s off and pausing to rethink.
What We Found
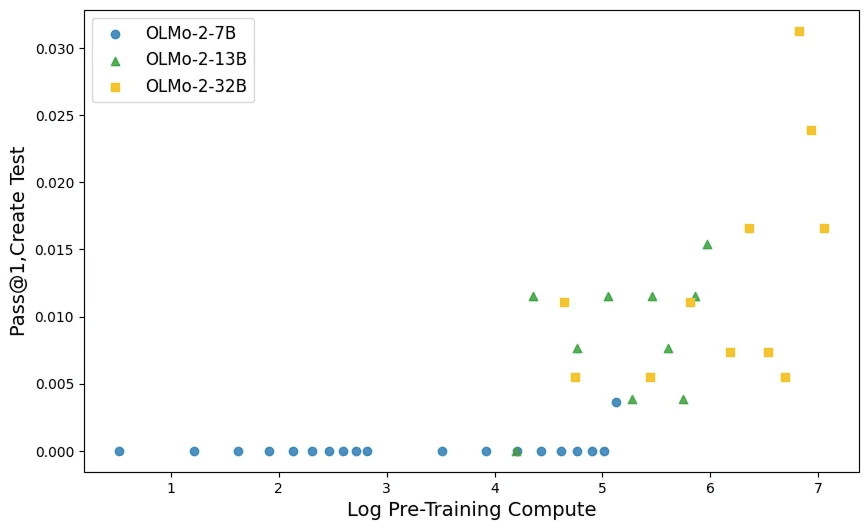
1. Reflection Starts Earlier Than We Expected
We found evidence of reflection even in relatively small models, early in their training. For example, an OLMo‑2 model with 7B parameters and ~198B training tokens was able to recognize and correct errors in reasoning. With additional training compute, reflection became stronger and more consistent.
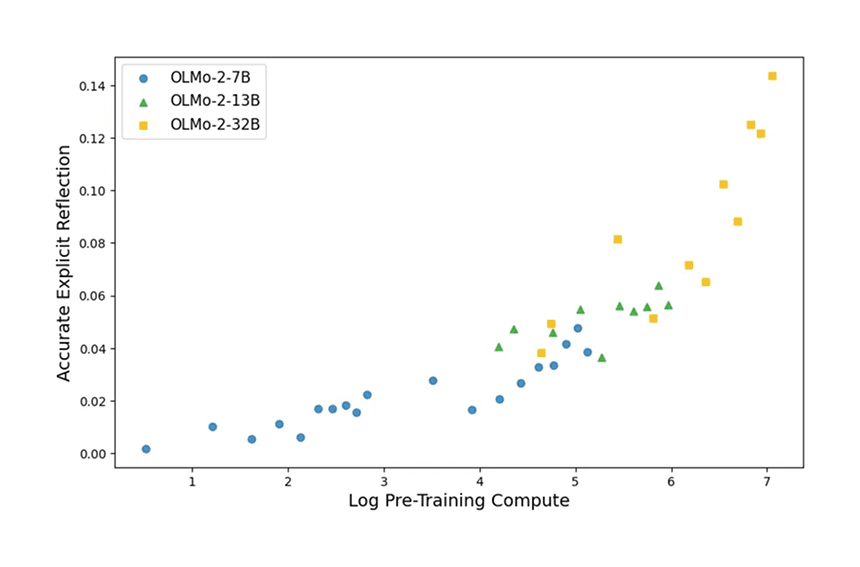
2. A Simple Prompt Like “Wait,” Makes a Big Difference
Appending a single word—“Wait,”—was often enough to prompt the model to reconsider and correct its answer. This significantly improved outcomes and increased the rate of explicit reflection, suggesting reflection can be elicited, not just learned.
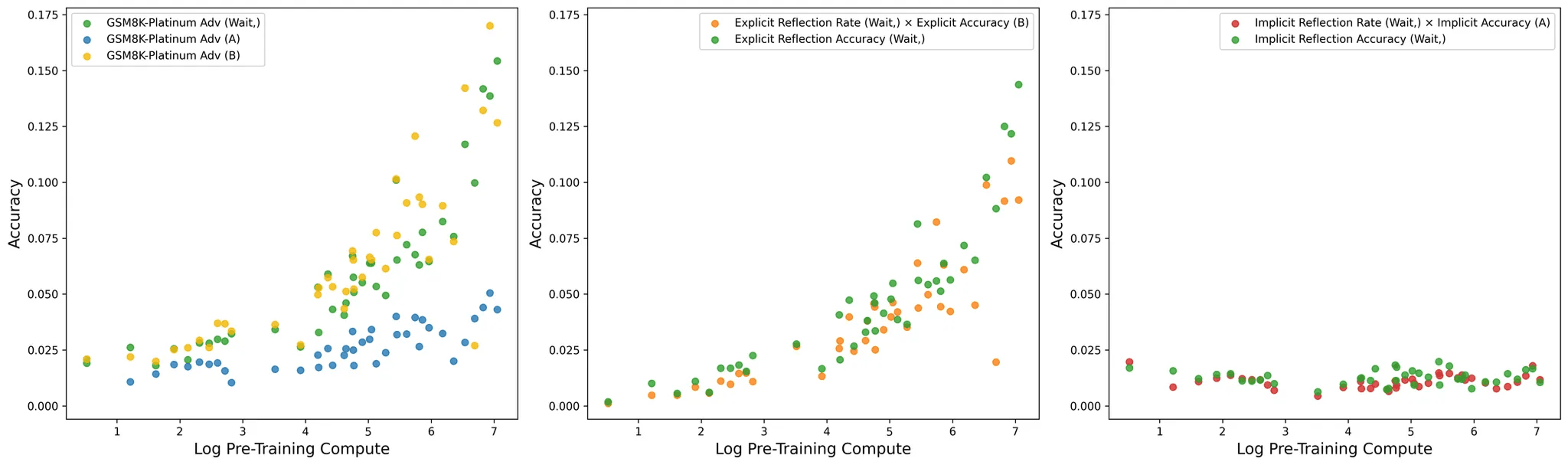
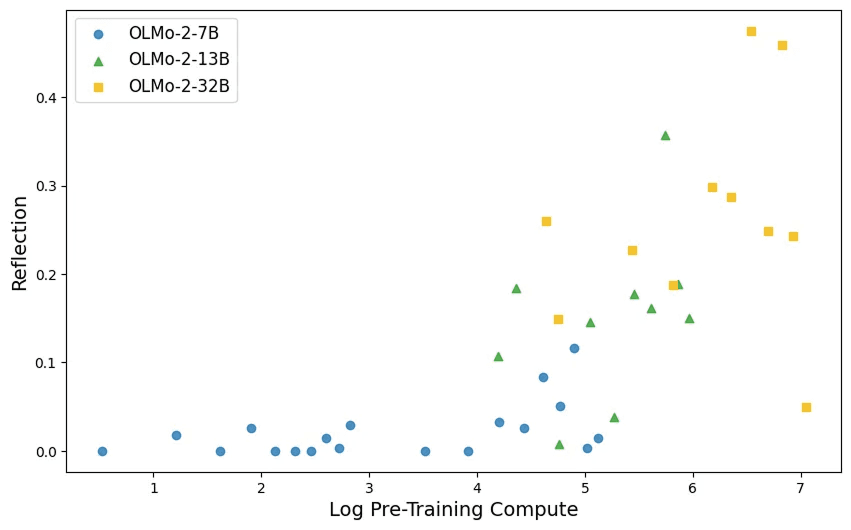
3. Self‑Reflection Is Harder, but It Emerges Too
When we asked models to review their own earlier mistakes—giving a second chance on problems initially answered incorrectly—success rates were lower (these items are, by definition, harder). Still, reflection increased with training; in some tasks, models began reflecting before they consistently corrected, hinting reflection may precede deeper reasoning.
Why This Matters
- Training strategy: our measurements suggest ways to target datasets and curricula that improve reflection at scale.
- Evaluation: traditional benchmarks can miss early signs of reflection. Our framework distinguishes implicit vs explicit reflection during pre‑training.
- Safety & alignment: a model that can spot and fix its mistakes is easier to trust in reliability‑critical applications.
Looking Ahead
This work is a first step. There’s more to learn about how and why reflection arises—what training data promotes it, which reasoning types are easiest to reflect on, and how reflection in pre‑training connects to stronger reasoning at inference time.
We hope the tools and datasets we’ve released help others explore these questions too.